
First Speakers Confirmed for Latch-Up 2025
The first batch of speakers for Latch-Up 2025, the conference dedicated to free and open-source silicon and its surrounding ecosystem, have been confirmed — and if you haven’t registered to talk or attend yet, there’s still time before the doors open in sunny Santa Barbara, California, on the 2nd to the 4th of May 2025.
Speakers confirmed in the first batch are:
Xiaoke Su, the One Student One Chip Initiative: Learning to Build RISC-V Chips from Scratch with a Massively Open Online Course (MOOC) The “One Student One Chip” (OSOC) initiative was launched by the University of Chinese Academy of Sciences in 2019. The initiative guides students through designing a RISC-V processor chip from scratch, including tape-out, developing a simple operating system, running it on the chip, running the real game Legend of Sword and Fairy, and completing the physical design process using open-source EDA tools. This enables students to understand the entire processor chip design process. As of February 2025, the total number of OSOC enrolments has exceeded 10,000. This talk introduces the implementation of the “One Student One Chip” initiative and the outcomes of open-source chip talent cultivation.
David Hossack, Modelling Digital Signal Processing to Confirm Frequency Response and Performance A simple methodology for modelling digital signal processing was introduced at ORConf 2024. This has been greatly extended and now includes performance measurement (signal and band limited noise level, IMD, THD etc), fixed point arithmetic modelling, and frequency response determination - both directly at the transfer function level, and extracted from time domain simulation. THis talk looks at that work.
Joaquin Matres, Revolutionise Your Chip Design with GDSFactory GDSFactory is a powerful Python library for designing a wide range of complex systems, including photonic circuits, analogue devices, quantum components, MEMs, 3D-printed objects, and PCBs. With GDSFactory, you can create and refine your designs using Python or YAML, perform rigorous verification through Design Rule Checking (DRC), Layout Versus Schematic (LVS) checks, and simulations. Additionally, it facilitates automated lab testing to ensure that your fabricated devices meet precise specifications, streamlining the entire design-to-fabrication workflow.
Alex Mykyta, PeakRDL: An Accessible and Extensible SystemRDL CSR Automation Toolchain Nearly every IP core, peripheral, and SoC requires a software register interface. Along with that you need software headers, test APIs, and good documentation. Wouldn’t it be great to automate all of this using a single source of truth? Fortunately a ready-to-use toolchain already exists! PeakRDL is a free and open register map automation toolchain that is designed around SystemRDL - an industry-standard CSR specification language. In this talk, discover how these silicon-proven tools can be used to generate synthesisable RTL, impressive documentation, software abstraction layers, and be extended using an intuitive Python API. This presentation will also review the latest updates to the PeakRDL and SystemRDL compiler tools, as well as a preview of what is planned for the future.
Adruth Vasudevan Srinivasan, BenchBot 2.0: Cleaner Code, Better Coverage, and Expanded Simulator Support BenchBot is an open-source Python tool that automates the creation of OSVVM-compliant testbenches for VHDL designs. It uses YAML configurations to define key parameters and generates a structured test environment. The generated testbenches include essential components such as clock and reset generators, stimulus handlers, and watchdog mechanisms. BenchBot also supports modular and distributed test development within the OSVVM framework. In this talk, we will first discuss the complete refactoring of BenchBot’s Python codebase. Next, we will highlight the new features added to the generated VHDL testbenches. Additionally, we will discuss how BenchBot now supports more simulators, including NVC, expanding its usability across different verification environments.
Zachary Sisco, A Memory Design Language for Automated Memory Technology Mapping During the chip development process, engineers need to target different technologies to support different deployment platforms, such as simulation, ASIC and FPGA technologies. The conventional approach leads to a brittle code base, with multiple but subtly different technology-specific blocks of code describing the same semantic behaviour, increasing the burden on verification, agility, and extensibility. The insight in this work is incorporating an abstract memory representation into the HDL which is “write once, map anywhere,” meaning the memory representation has a rich enough semantics to target all of the relevant technologies using a single generic interface. This DSL, called a memory design language, enables automated technology mapping for memories. Further, for designs coming from other HDLs which are already mapped to a specific technology, I also present a hardware decompilation-based memory inference technique which lifts memories from a gate-level design to an abstract memory block, enabling automated technology re-targeting, a holy grail for digital designers.
Larry Doolittle, cdc_snitch: Checking Logic Designs for CDC Anti-Patterns Almost all real-world logic designs (FPGA and ASIC) require use of multiple clock domains. Techniques have been established to move information between clock domains (clock domain crossing, shortened to CDC). It is easy, however, to lose track of where CDC happens in a large HDL code base, especially one that evolves as a collaborative effort. Our cdc_snitch tool leverages Yosys’ logic synthesis and transformation capabilities to analyse a design and find anti-patterns of CDC design. This visibility has helped us improve our code quality, and is now a part of our continuous integration (CI) workflow.
Arman Samimi, fplib: A Fixed-Point Math Library for SystemVerilog fplib is a synthesisable SystemVerilog library for working with fixed-point (FP) numbers. This library abstracts out the error-prone task of working with FP numbers, such as keeping track of the integer and fractional bits (the binary point) when doing add/multiply operations. fplib works by (ab)using SystemVerilog interfaces to encapsulate a normal logic vector as well as the parameters for the number of int/frac bits into a single object which can be passed through modules (in the absence of proper language support like in VHDL).
Olof Kindgren, SERV, QERV, and HERV: Meet the Family of the World’s Smallest RISC-V CPUs The award-winning SERV is the world’s smallest RISC-V CPU and has already proven that you can get a real RISC-V for a fistful of gates. The trade-off is that it is slower than most other RISC-V cores, which is fine for most uses of SERV. But sometimes you need a little more performance and for those cases, we got just the thing for you. Meet QERV, the quadrupled SERV! QERV is three times faster than SERV while only being approximately 20% larger, which means that it’s still the world’s smallest RISC-V CPU, only faster. Or why not try HERV, 5 times faster and 50% larger. This presentation will look deeper into QERV and HERV, what makes them so small and how they compares to SERV when it comes to power efficiency, performance and area. We will also look at future features and optimisations in the pipeline and investigate what you can get for a few gates more.
Stefan Wallentowitz, Stronger Together: Europe Unites for Open-Source EDA Europe is stepping up in Open Source Chip Design by funding various parts of the ecosystem. In particular, currently Open Source EDA tools are in the focus, attracting 40+ million Euro in funding. This presentation gives a brief overview of how FOSSi Foundation played an integral role in this effort and how the community will benefit from, and which challenges are ahead.
Dan Ruelas-Petrisko, bsg_pearls: Effortlessly Synthesizable Building Blocks That Work Right Out of the Shell Accelerating agile hardware design requires aggressive reuse of libraries and methodologies. While libraries like Basejump STL, PULP Platform Common Cells and Chipyard excel at providing portability layers and low-level components (e.g. FIFOs, memories), and SoCs rely on hardened IP blocks for larger components (e.g. off-chip PHYs, processor cores), there remains a gap in reuseable blocks between these levels. bsg_pearls bridges this gap by offering a library of mid-level synthesizable components - such as SDR links, DDR links, clock generators, LPDDR controllers - that can be seamlessly integrated into soft designs. Each submodule contains SystemVerilog design files, a synthesizable testbench, vendor-agnostic TCL constraints and technology-agnostic placement guidelines. By construction, pearls are highly runtime configurable and (mostly) decoupled from external timing paths, enabling early hardening in the design process. This drastically reduces full-chip iteration time while maintaining flexibility in immature RTL. In this talk, I will present the philosophy and architecture of bsg_pearls; explore their use in real-world chip designs; discuss integration plans with open-source tooling; and invite feedback from the open-source hardware community to drive adoption!
Latch-Up is, as always, free to attend. If you are able to, however, please consider helping to support the event with a “Pay What You Want” ticket via donation. If you are attending Latch-Up on behalf of a company, please encourage your employer to donate in the form of a professional ticket.
If you’re as eager as us to hear from the above speakers, and more to come, you can register now on the Latch-Up 2025 website - and we look forward to seeing you there!

FOSSi Foundation Joins Google Summer of Code (GSoC) 2025
The FOSSi Foundation is once again proud to announce its selection as a mentor organisation for the Google Summer of Code (GSoC) 2025, a programme which provides new contributors to open-source projects with a Google-funded stipend and access to mentors from supporting organisations.
“To act as a first point of reference, we have prepared a list of project ideas,” explains FOSSi Foundation director Jonathan Balkind. “As a mentee you are free to base your project on one of these ideas, but remember that it is your idea we are looking for, and you should come up with an idea that you want to work on, in conjunction with one of our mentors. Your job is to write a realistic project proposal (of appropriate scope) to show us that you have a good idea of the work involved, and discuss the idea with our mentors to get feedback.”
Given the expansive nature of the free and open-source silicon ecosystem, there are no shortage of ideas for potential contributions - and the ideas outnumber the slots the FOSSi Foundation is likely to be granted. As a result, priority will be given for well-written project ideas - and we encourage would-be mentees to get involved with the community as early as possible to help flesh out their proposals.
More information is available in Jonathan’s blog post, including the address for applications; you can find additional resources in Google’s documentation. Applications close on the 8th of April, a hard deadline set by Google’s own project timeline.

YosysHQ Boasts of 500k-LUT Space Chip Support
The nextpnr open-source route-and-place tool has reached heady new heights as its maintainer celebrates support for the largest FPGA yet: a 500,000-LUT space-grade part from NanoXplore, as part of a partnership with the European Space Agency (ESA).
“We have now added support in nextpnr for the largest FPGA so far supported by open-source tooling! 500,000 LUTs,” Yosys maintainer YosysHQ writes in its announcement. "In November 2024 we successfully concluded the European Space Agency-funded project in collaboration with NanoXplore, known for their space rated FPGAs.
“The nextpnr tool provides developers with a flexible and customizable option for designing for NG-Ultra FPGAs, offering increased reliability through the ability to cross-verify designs using two independent tools. Future work could focus on expanding support within nextpnr to cover additional FPGA primitives, such as high-speed I/O blocks and SoC integration making it more useful for high complexity designs.”
“The NG-Ultra is the largest device implemented in nextpnr, allowing us to push the tool’s limits at scale,” adds Matt Venn, YosysHQ’s chief sales officer. “Unlike previous open-source place-and-route tools that relied on imagined architectures or reverse engineering, this work is unique because the vendor provided architecture details. However, since vendor-specific place-and-route implementations were not included, we had to develop independent solutions to address architectural limitations, making this a significant step forward in open-source FPGA tooling.”
“This activity explored cutting-edge algorithms for the place-and-route step, expanding the open-source toolchain to large-scale FPGAs,” notes ESA technical officer Filomena Decuzzi. “The project allowed the European space-grade FPGA ecosystem to open up to the open-source community, enabling participation and improvements in the ecosystem.”
More information is available on the ESA website.

Sylvain Munaut Turns Two Tiny Tapeout Projects into an SDR
Sylvain Munaut has proven that Tiny Tapeout, the project from Matt Venn and colleagues to provide an affordable route to manufacturing free and open-source silicon designs in hardware through a multi-project chip approach, can deliver functional devices - by combining two projects from Tiny Tapeout 6 into the main components of a working software-defined radio (SDR).
“Tiny Tapeout allows anyone to easily design custom silicon using the SkyWater SKY130 Open-PDK Process Design Kit and get it taped-out at low cost by combining hundreds of projects on the same chip,” Sylvain explains. “On the Tiny Tapeout 6 shuttle Carsten Wulff taped out an eight-bit SAR Successive Approximation ADC, and on the Tiny Tapeout 7 shuttle Kolos Koblász taped out an RF mixer. I decided to combine both of these, a Glasgow Interface Explorer USB interface, and some GNU Radio software to build a small demo SDR!”
The sixth and seventh Tiny Tapeout production runs saw a range of contributions from chip designers new and old, but it’s just two of those - all of which are present on the multi-project chip supplied to designers - which are at the heart of Sylvain’s project. The first was a modification of an existing SAR ADC design by Carsten Wulff, originally put together for a smaller process node; the second Kolos Koblász’ RF mixer.
“It just so happens that the ADC has a differential input and the RF mixer has a differential output,” Sylvain explains of the designs, which were submitted independently, “so it’s almost like they were made to be connected together.” By doing exactly that, and adding custom firmware for the Raspberry Pi RP2040 microcontroller on the chips’ carrier boards plus a Glasgow Interface Explorer to provide a USB interface compatible with GNU Radio, Sylvain could turn them into a basic SDR.
The project is detailed in a video on Sylvain’s YouTube channel.
Efabless Shuts Down, Tiny Tapeout Seeks a Path Forward
Semiconductor design platform Efabless has announced its immediate operational shutdown in the face of unspecified “funding challenges” - a move which has left Matt Venn’s Tiny Tapeout project seeking alternative paths to continue having contributors’ projects manufactured as physical chips.
“Due to funding challenges,” a notice on the Efabless website reads, “Efabless has shut down operations until further notice. We regret any inconvenience and will provide updates as available.”
“For anyone who doesn’t know, Efabless has played a central role in the open source silicon community, running the first open source silicon shuttles, the community slack channels, developing the tools and supporting a wide range of projects, including ours,” Tiny Tapeout’s Matt Venn explains. "If you’ve ever been to one of our workshops, visited our website, watched one of our videos you’ll know that Efabless has supported Tiny Tapeout since the beginning. We wouldn’t exist if not for their support.
“Right now we have TT08 awaiting packaging and TT09 is still in the SkyWater Technology fab. These chips represent a huge investment of time and energy from hundreds of people and we currently don’t know if we’ll receive them. We are prepared to offer a refund to all our affected customers in the case we aren’t able to ship those chips. The current TT10 shuttle and future Sky130 shuttles are paused while we explore options for Sky130 and other processes.”
That doesn’t mean Matt and colleagues are giving up on Tiny Tapeout, though - quite the opposite. “We already have an existing relationship with IHP, which offers a similar 130nm process. We’ve completed two experimental tapeouts with them, and our next public shuttle will likely be with them in June. We are also trying to find a route to manufacture on GlobalFoundries GF180, an existing open source PDK. If you’re a foundry and want to play a central role in the future of open source silicon, please get in touch!”
Updates will be published to the Tiny Tapeout website.

OpenTitan Production Begins
Open silicon specialist lowRISC has announced that its partnership with Google and the other members of the OpenTitan project has reached the biggest milestone yet: production of the open hardware root of trust (RoT) chip for use in commercially-shipping Chromebooks and more.
“We’re excited to share that Google has just announced that fabrication has commenced on production OpenTitan silicon by Nuvoton Technology Corporation,” lowRISC says in its announcement. “Product integrations have begun to intercept Chromebooks shipping later this year, with datacenter integrations following shortly after. This is the first broadly-used silicon RoT chip at Google to have a fully transparent design and origin.”
“OpenTitan is the first open-source silicon project to reach commercial availability based on the engineering samples we released last year,” adds Cyrus Stwoller and Miguel Osorio, from Google’s OpenTitan team. "The OpenTitan project started from scratch in 2018 with a coalition of commercial, academic, and not-for-profit partners. The OpenTitan project is hosted by lowRISC CIC in Cambridge, UK. Google and project partners - Nuvoton, ETH Zurich, G+D Mobile Security, lowRISC, Rivos, Seagate, Western Digital, Winbond, zeroRISC, and a number of independent contributors - provide open source hardware register-transfer level (RTL) and design verification (DV) code, along with integration guidelines, and reference firmware to drive adoption throughout industry.
“With OpenTitan, we’ve introduced brand new methodologies for how commodity chips get designed that are increasingly economical moving forward. OpenTitan provides Google with a high-quality, low-cost, commoditised hardware RoT that can be used across the Google ecosystem. This will also facilitate the broader adoption of Google-endorsed security features across the industry. The fabrication of production OpenTitan silicon is the realisation of many years of dedication and hard work from our team. It is a significant moment for us and all contributors to the project. OpenTitan’s broad community has been critical to its success.”
More information is available on the OpenTitan website; the project’s source is published on GitHub under the permissive Apache 2.0 licence.

FuseSoC Launches User Survey
FuseSoC maintainer and FOSSi Foundation director Olof Kindgren has opened a user survey for the project, open both to those who actively use the tool and those who do not - and if you’re in a hurry, you’ll be pleased to hear it’s just one question long.
“Since its inception in 2011, FuseSoC has arguably become the most popular package manager for IP cores,” Olof explains. "It is used inside all kinds of companies from small start-ups to some of the world’s largest chip making companies. It is also popular in both academia and among hobbyists. Still, it’s a small open source project without any dedicated sustainable funding and right now we ask for your help by filling out this extremely short survey to show your support.
“For a project like FuseSoC, strength is in numbers. If we can show that there are many FuseSoC users out there, it will be much easier to convince others to add FuseSoC support for their cores which further expands the ecosystem to everyone’s benefit. It will also be much easier to approach funding opportunities if we can show that there are already industry and academia users who will benefit from a thriving FuseSoC ecosystem.”
And showing your support will not only help the FuseSoC developers," Olof adds, “but also yourselves. If we can find more sustainable funding, we will also stand a much better chance to implement all the nice features you’re asking for and fix all the bugs you’ve been complaining about. Sounds like a win-win, doesn’t it?”
The one-question survey - two if you count adding your name, four if you’re adding optional information on your profession affiliation and location - is open now on Google Docs.

First-Boot for Space-Grade SHAKTI Chip
The Indian Institute of Technology Madras (IIT Madras) has announced a successful first-boot of a natively-fabricated SHAKTI-based RISC-V processor destined for use in space, dubbed IRIS-LV: the Indigenous RISC-V Controller for Space Applications.
“After RIMO in 2018 and MOUSHIK in 2020, this is the third SHAKTI chip we have fabricated at SCL Chandigarh and successfully booted at IIT Madras,” says IIT Madras director V. Kamakoti. “That the chip design, chip fabrication, chip packaging, motherboard design and fabrication, assembly, software and boot - all happened inside India, is yet another validation that the complete semiconductor ecosystem and expertise exists within our country.”
“We at ISRO the Indian Space Research Organisation are very happy that the IRIS Controller conceived by IISU based on SHAKTI processor of IIT Madras could be successfully developed end-to-end with Indian resources,” adds ISRO chair V. Narayanan. “This marks truly a milestone in ‘Make in India’ efforts in semiconductor design and fabrication. I congratulate all the teams involved, especially the IISU ISRO Inertial Systems Unit Team led by Sri Padmakumar ES and the IIT Madras team led by Prof. V. Kamakoti. I am sure that this high-performance controller, realised as per our requirements, will contribute significantly to future embedded controllers for space mission-related applications. It is planned to flight test a product based on this controller shortly and performance will be confirmed.”
“SCL is proud to be associated with IIT Madras and ISRO in the successful development of IRIS-LV Processor,” says SCL Chandigarh’s director general Shri Kamaljeet Singh, whose company fabricated the part. “IRIS-LV Processor is fully indigenous and fabricated in SCL’s 180nm technology node encompassing mask frame design, GDS preparation, and testing. Post-silicon design validation and extensive electrical testing on wafer-level was conducted at SCL in close collaboration with the IIT Madras team. SCL is committed and continually working in association with academia and startups to facilitate and achieve Atmanirbharta Self-Respect in the realisation of niche products.”
More information on the SHAKTI project is available on the official website. A video announcing IRIS-LV is available on YouTube.
Researchers Pinpoint "Sweet Spot' for Sub-Threshold RISC-V Cores
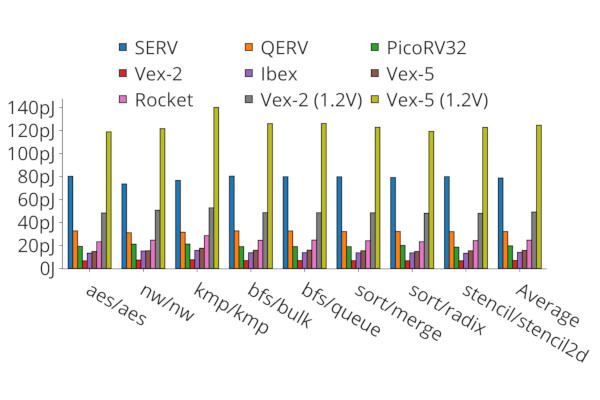
Researchers from the Norwegian University of Science and Technology (NTNU) in Trondheim have published a paper on optimising energy-efficiency in RISC-V designs for use in ultra-low-power sub-threshold cores - using a custom cell library to synthesise company RISC-V cores including SERV, QERV, and PicoRV32 in order to find the “sweet spot” for performance and power consumption.
“Our goal in this paper is to understand how to maximise energy efficiency when designing standard-ISA processor cores for sub-threshold operation,” the team explains. "We hence develop a custom sub-threshold library and use it to synthesise the open-source RISC-V cores SERV, QERV, PicoRV32, Ibex, Rocket, and two variants of Vex, targeting a supply voltage of 300mV in a commercial 130nm process. SERV, QERV, and PicoRV32 are multi-cycle architectures, while Ibex, Vex, and Rocket are pipelined architectures.
"We find that SERV, QERV, PicoRV32, and Vex are Pareto-optimal in one or more of performance, power, and area. The 2-stage Vex (Vex-2) is the most energy efficient core overall, mainly because it uses fewer cycles per instruction than multi-cycle SERV, QERV, and PicoRV32 while retaining similar power consumption. Pipelining increases core area, and we observe that for sub-threshold operation, the longer wires of pipelined designs require adding buffers to maintain a cycle time that is low enough to achieve high energy efficiency. These buffers limit the performance gains achievable by deeper pipelining because they result in cycle time no longer scaling proportionally with pipeline stages.
“The added buffers and the additional area required for pipelining logic however increase power consumption, and Vex-2 therefore provides similar performance and lower power consumption than the 5-stage cores Vex-5 and Rocket. A key contribution of this paper,” the researchers conclude, “is therefore to demonstrate that limited-depth pipelined RISC-V designs hit the sweet spot in balancing performance and power consumption when optimising for energy efficiency in sub-threshold operation.”
The full paper is available in preprint on Cornell’s arXiv server
Philip Zucker Puts EBMC to Work Comparing Two Verilog CPUs
Self-described “physics/computer boy” Philip Zucker has written up a project to compare two Verilog CPU core implementations using an EBMC test-bench.
“About a year ago my friends and I built a 4-bit CPU out of a kit from AliExpress,” Zucker explains. "It’s a lot of fun. I also think the system is so simple that is is kind of a nice target for tinkering around with formal methods. From my understanding, the digital design world orbits around VHDL and Verilog. A confusion that can arise when a programmer sees Verilog is that it is just another programming language. Yes and no. These languages play multiple roles. They can be seen and used as a sort of netlist/circuit description language, describing which sub-pieces are connected and how. But they can also be seen as a programming language for describing the behaviour of a digital system and that is how they are used in simulation of these circuits.
“As well as manual simulation, I can also make a testbench to run the CPUs through EBMC, which is a bounded model checker for Verilog. EBMC is a cousin of CBMC and Kani for C and Rust respectively, which I’m pretty bullish on. Using a bounded model checker lets the instruction run be symbolically chosen, which is more complete and easier than me writing a ton of programs (I suppose I could fuzz them too? Wouldn’t be so bad). The key is to be feeding the same stuff into both versions of the CPU. Even though I don’t have confidence on either implementation, any difference in behaviour is something to look into. In the end of the day, this is almost all formal methods can be. Comparing one way of saying a thing to another. Often these are a logicy spec and a programmy implementation, but they can be two programs too.”
The full write-up is available on Philip’s website.

News In Brief
- Olof Kindgren has announced improvements to SERV: "not only is it three LUTs smaller on an iCE40, it also executes branches, memory operations, and left-shifts 1.5% faster."
- University of Cambridge researchers shown off TestRIG, for randomised testing of RISC-V CPUs.
- RISC-V International has announced its first online "hackathon," the sensibly-named RISC-V Hackathon Online: 10th to the 16th of April 2025.
- Newswire service Reuters cites "two sources briefed on the matter" as telegraphing China's intention to push the use of RISC-V for sovereign chip efforts.
Have feedback or news for inclusion in a future newsletter? Please send this to ecl@fossi-foundation.org.
Subscribe to get El Correo Libre direct to your inbox.