
ORConf 2025 Kicks Off - First Talks Announced!
The countdown to ORConf 2025 has officially begun, and we’re thrilled to announce that the first wave of talks is now live at orconf.org! This year’s gathering will take place in the vibrant city of Valencia, Spain - a cultural hotbed and the perfect backdrop for the free and open source silicon community to connect, innovate, and inspire.
Highlights from the First Set of Talks
The submissions are already shaping up into a powerhouse line-up. Here’s a peek at some of the talks you’ll get to experience:
- Open Hardware Success Stories - Real-world applications and lessons learned from deploying open-source silicon.
- Next-Gen Toolchains - Explorations into new and improved flows for digital and analogue design.
- RISC-V Advancements - Fresh perspectives and cutting-edge work expanding the RISC-V ecosystem.
- Open Source EDA Innovations - Updates on the latest tools, including integration strategies and optimisation techniques.
- Academic Perspectives - Research-driven insights on formal verification, modeling, and simulation frameworks.
And that’s just the beginning - more talks are being added as they’re confirmed, so keep checking back for updates.
Join the Movement - Register Now
Registration is officially open! Whether you’re deep in the trenches of free and open source silicon or just curious to learn more, ORConf is the place to be. There’s no better forum to engage with engineers, researchers, hobbyists, and industry leaders shaping the future of free and open source hardware.
Visit orconf.org to grab your spot.
Sponsorship Opportunities Still Available
Want to support the open hardware ecosystem while putting your brand front and centre with a passionate and influential community? Sponsoring ORConf is a powerful way to do just that. Sponsors get visibility both online and on-site, plus the satisfaction of fuelling the movement.
Reach out through orconf.org to explore the sponsorship packages - we’d love to collaborate.
Come for the talks, stay for the tapas. ORConf Valencia 2025 is going to be a blast. Let’s build the future of free and open source silicon!
-Philipp Wagner, FOSSi Foundation Director
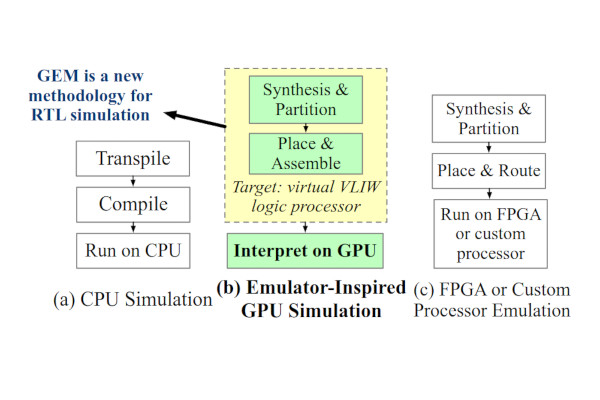
GEM Delivers GPU-Accelerated RTL Simulation
Researchers from Peking University, the Beijing Advanced Innovation Centre for Integrated Circuits, and Nvidia have released the source code for GEM - the GPU-accelerated emulator-inspired RTL simulation system.
“We present a GPU-accelerated RTL simulator addressing critical challenges in high-speed circuit verification,” the team writes in the abstract to the GEM paper. "Traditional CPU-based RTL simulators struggle with scalability and performance, and while FPGA-based emulators offer acceleration, they are costly and less accessible. Previous GPU-based attempts have failed to speed up RTL simulation due to the heterogeneous nature of circuit partitions, which conflicts with the SIMT (Single Instruction, Multiple Thread) paradigm of GPUs.
“Inspired by the design of emulators, our approach introduces a novel virtual Very Long Instruction Word (VLIW) architecture, designed for efficient CUDA execution. We also design a flow that maps circuit logic to the architecture in a process analogous to the FPGA CAD flow. This architecture mitigates issues of irregular memory access and thread divergence, unlocking GPU potential for RTL simulation. Our solution achieves up to 64x speed-up over the best CPU simulators, democratising high-speed RTL simulation with accessible hardware and establishing a new frontier for GPU-accelerated circuit verification.”
GEM, the paper for which was accepted for presentation at the Design Automation Conference 2025 and which was nominated for best paper, isn’t being kept behind closed doors: its developers have released the project’s source code under the permissive Apache 2.0 licence, though being CUDA-based it’s designed to run exclusively on Nvidia’s graphics hardware. “The synthesis and mapping is slower than the compiling/elaboration process of CPU-based simulators,” its creators admit. “But it is a one-time cost and your design can be simulated under different testbenches without re-running the synthesis or mapping.”
More information is available on the Nvidia research site, along with a preprint of the paper; the project source code has been published to GitHub under the Apache 2.0 licence.

Tiny Tapeout Gets a Slick New Chip Viewer
Matt Venn’s Tiny Tapeout project, which allows contributors to have their free and open source silicon designs produced as an application-specific integrated circuit (ASIC) at an extremely low cost, has received a major upgrade in the form of a new interactive multi-layer chip viewer.
“Our chip viewer just got an upgrade,” Matt explains of the upgrade, which is live now. “Now you can see microscope images, GDS Graphic Design System layout, and local interconnect and jump straight to project files. Spot something cool? Dive right into the design.”
The new viewer extends the existing system with a multi-layer look at what goes into each multi-project chip. It starts with a photograph of the bare silicon die, taken though a high-magnification microscope; GDSII data can be visualised too, as can the local interconnect layer. Multiple layers can be stacked, allowing the GDSII data to be overlaid on the die photo to highlight hard-to-see details - and it’s also possible to enable a clickable “shuttle map” which lets you select any given project to be taken right to its source code.
The new viewer is live on the Tiny Tapeout website for the Tiny Tapeout 6 and Tiny Tapeout 7 production runs; the project is currently accepting contributions for Tiny Tapeout IHP25b, which makes the move to a new semiconductor fabrication facility in the face of the closer of previous project partner Efabless. Additional imagery examples are available on Matt’s Mastodon post.

…and Announces GlobalFoundries 180MCU Support
Matt Venn has also announced that Tiny Tapeout is to gain support for manufacturing on the GlobalFoundries 180MCU process, with a minimum viable chip expected to be submitted by September this year.
“We’re kicking off work adding GlobalFoundries 180MCU to the Tiny Tapeout ecosystem,” Matt writes of the project’s expansion. "Thanks to support from Tillitis AB, we have started working on the first 2 of 4 work packages.
"1: Closing the submission loop with a minimum viable chip. This will be submitted to either wafer.space or the Synopsys sponsored shuttle ~September 2025. 2: Minimum viable Tiny Tapeout chip with digital designs only. This will be submitted to a wafer.space shuttle ~Oct-Nov 2025.
“We’re grateful for early letters of support from wafer.space, the IEEE Electron Devices Society, and Synopsys Inc. - all reinforcing the momentum for regular GF shuttles aimed at learning, training, and workforce development.”
More information is available in Matt’s LinkedIn post, along with a call for sponsorship to address the remaining four work packages and add “complete support for analogue and mixed signal” designs.
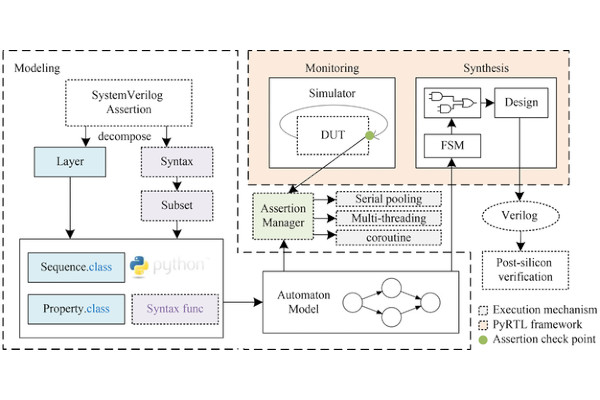
PyABV Brings Assertion-Based Verification to PyRTL
Researchers from China’s National University of Defence Technology have released a framework which adds assertion-based verification to PyRTL, dubbed PyABV.
“Our goal was to bring assertion-based verification directly into the Python workflow,” explains corresponding author Tun Li of the team’s work on PyABV, “empowering designers to catch subtle bugs early and reduce turnaround times.”
“PyABV represents assertions as Python objects based on standard automata semantics, letting designers write temporal checks in clear, high-level code,” the team writes. “An assertion manager integrates with the PyRTL simulator for real-time monitoring, using multithreading and coroutine techniques for efficiency. For hardware verification, each assertion is automatically translated into a dedicated monitor circuit that preserves the original verification intent during synthesis.”
The idea behind the project is to embed “familiar, industry-standard assertion techniques into a Python workflow,” the researchers explain. There is, of course, a cost: tested on real-world designs, PyABV increased simulation runtimes by 30-40 per cent - reducible to 20-29 per cent through the use of optimised coroutines, the team says. Turning assertions into monitoring circuits for FPGA implementations of designs, meanwhile, added around 1.5 per cent to the total logic unit count.
The team’s work has been published in the journal Frontiers of Computer Science under closed-access terms, while the source code is available on Gitee under the permissive BSD three-clause licence “for immediate adoption and community-driven enhancements.”

RISC-V Boot and Runtime Services Spec Review Open
Task group chair Sunil V L has announced the opening of public review for the RISC-V Boot and Runtime Services Specification - but those interested in providing feedback will have to do so before the 18th of July.
“We are delighted to announce the commencement of the public review period for the RISC-V Boot and Runtime Services Specification,” Sunil wrote in a message to the RISC-V mailing list. “During the review period, we will gather corrections, comments, and suggestions for review by the BRS TG. Minor corrections and non-controversial changes will be directly incorporated. Any unresolved issues or significant proposed modifications will be summarised in the public review report. Provided no major changes are required, the Privileged Software HC will recommend ratification by both the Technical Steering Committee and the Board of Directors.”
The RISC-V BRS aims to define a standardised set of software capabilities to allow operating systems, hypervisors, and other “portable system software” to discover devices, boot, carry out system management, and other tasks. “The BRS specification is targeting systems that implement S/U privilege modes,” the current draft explains. “This is the expected deployment for OSVs and system vendors in a typical ecosystem covering client systems up through server systems where software is provided by different vendors than the system vendor.”
The current specification document is available, along with its source, on GitHub; feedback is sought as GitHub Issues, or as messages to the RISC-V isa-dev mailing list. The review period closes on the 18th of July 2025.
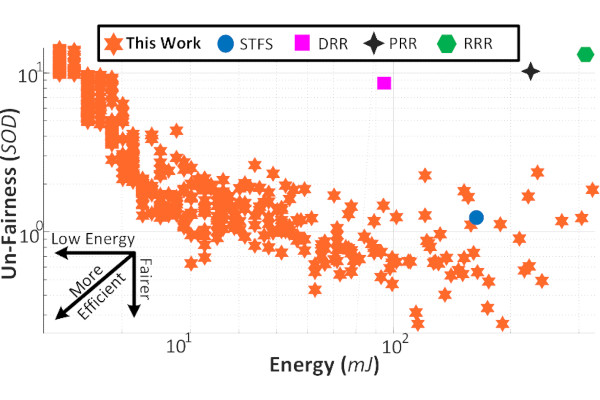
THEMIS Targets Fair Multi-Tenant FPGA Use
Researchers from Microsoft, North Carolina State University, and the University of Oxford have published a paper detailing THEMIS: Time, Heterogeneity, and Energy Minded Scheduling for Fair Multi-Tenant Use in FPGAs.
“Using correct design metrics and understanding the limitations of the underlying technology is critical to developing effective scheduling algorithms. Unfortunately, existing scheduling techniques used incorrect metrics and had unrealistic assumptions for fair scheduling of multi-tenant FPGAs where each tenant is aimed to share approximately the same number of resources both spatially (in space) and temporally (in time),” the researchers explain.
"This paper proposes an improved fair scheduling algorithm that fixes earlier issues with metrics and assumptions for ‘fair’ multi-tenant FPGA use. Specifically, we claim three improvements. First, we consider both spatial and temporal aspects to provide spatiotemporal fairness - this improves a recent prior work that assumed all tasks would have the same latency. Second, we add the energy dimension to fairness: by calibrating the scheduling decision intervals and including their energy overhead, our algorithm offers trading off energy efficiency for fairness. Third, we consider previously ignored facts about FPGA multi-tenancy, such as the existence of heterogeneous regions and the inflexibility of run-time merging/splitting of partially reconfigurable regions. We develop and evaluate our improved fair scheduling algorithm with these three enhancements.
“Inspired by the Greek goddess of law and personification of justice, we name our fair scheduling solution THEMIS: Time, Heterogeneity, and Energy Minded Scheduling. We implemented our solution on Xilinx Zedboard XC7Z020 with real hardware workloads and used real measurements on the FPGA to quantify the savings of our approach. Compared to previous algorithms, our improved scheduling algorithm enhances fairness between 24.2-98.4% and allows a trade-off between 55.3x in energy vs. 69.3x in fairness. The paper thus informs cloud providers about future scheduling optimisations for fairness with related challenges and opportunities.”
The team’s work has been published in the journal IEEE Transactions on Computers under closed-access terms, with a preprint freely available on Cornell’s arXiv server. The project’s source code is available on GitHub under the permissive MIT licence.

SCI Gets UK Government Funding for CHERI Work
Cambridge-based SCI Semiconductor has received a government grant, worth up to 50 per cent of the overall project value, for work on producing devices based around the Capability Hardware Enhanced RISC Instructions (CHERI) standard - as part of the UK’s Defence Technology Exploitation Programme (DTEP).
“The UK government are keen to act on security by design and this project will leverage CHERI technology, a key technology to delivering this capability,” says SCI Semiconductor’s chief executive Haydn Povey of the grant.
“With over 70 per cent of critical vulnerabilities and exploits (CVEs) directly linked to software memory safety issues, which form the vast majority of cyber-attacks on critical systems, there is a clear need to address this systemic weakness. This project is directly focused on ensuring communication systems and active control systems are more robust, higher integrity, and are inherently secured again broad-based cyber-attacks.”
The grant, sponsored by the Ministry of Defence’s Directorate of Industrial Strategy and Exports (DISE), will see SCI work to bring CHERI - a standard designed to expand the RISC-V instruction set with intrinsic memory safety capabilities - into real-world applications. The company will work with Ultra, and receive half of the project value back through the DTEP grant.
More information is available on the SCI Semiconductor website.
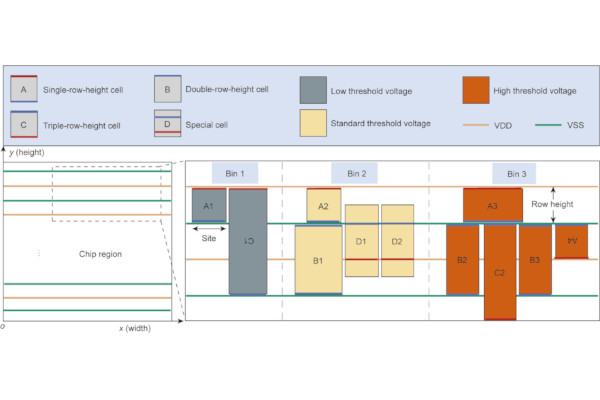
Researchers Claim an “Exact Algorithm” for Placement Optimisation
A team of computer scientists from Shanghai University and HEC Montréal boast of the development of an “exact algorithm” for mixed-cell-height circuit placement optimisation.
“Placement optimisation is a crucial phase in chip design, involving the strategic arrangement of cells within a limited region to enhance space utilisation and reduce wire length,” the team writes in paper’s abstract. "Chip design enterprises need to optimise the placement according to design rules to meet customer demands. While mixed-cell-height circuits are widely used in modern chip design, few studies have simultaneously considered the non-overlapping cells, rails alignment, and minimum implantation area constraints in the placement optimisation problems.
“This study involves preprocessing the non-linear parts and developing a mixed-integer linear programming model to reduce the cost of legalising chip placements for businesses. Furthermore, this study designs and implements an exact algorithm based on Benders decomposition, utilising dual theory to obtain an optimal cut and iteratively solve for the coordinates of cells. Numerical experiments across various scales validate the performance of the algorithm. Through a detailed analysis of the shape of the chip region division, the proportion of different types of cells, the total number of cells and bins, and their impact on the placement, we derive some potentially useful design insights that can benefit chip design enterprises.”
The researchers worked to developer a model which formalises the placement problem, turning it into a mathematical optimisation task. This model seeks to minimise placement cost measured in metrics including wire length and compactness while enforcing non-overlapping cell positions, accurate VDD/VSS alignment for signal integrity, and compliance with minimum implantation area constraints.
The team’s paper is available in the journal Engineering under open-access terms.
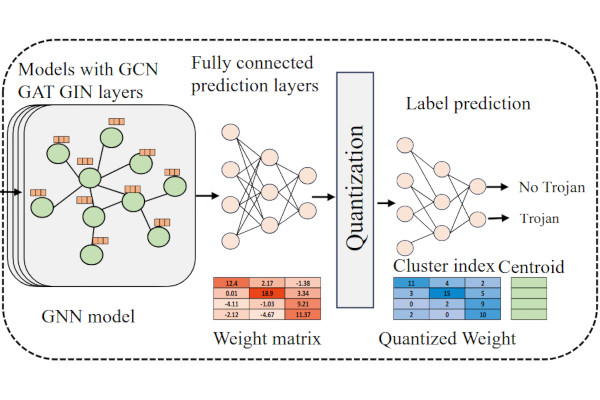
TROJAN-GUARD Looks to Secure RTL Designs
Researchers from the Universities of Connecticut and Minnesota have developed a framework which uses graph neural networks (GGN) to detect hardware Trojans inserted into RTL designs: TROJAN-GUARD.
“Chip manufacturing is a complex process, and to achieve a faster time to market, an increasing number of untrusted third-party tools and designs from around the world are being utilised,” the research team writes. "The use of these untrusted third party intellectual properties (IPs) and tools increases the risk of adversaries inserting hardware Trojans (HTs). The covert nature of HTs poses significant threats to cyberspace, potentially leading to severe consequences for national security, the economy, and personal privacy.
"Many graph neural network (GNN)-based HT detection methods have been proposed. However, they perform poorly on larger designs because they rely on training with smaller designs. Additionally, these methods do not explore different GNN models that are well-suited for HT detection or provide efficient training and inference processes.
“We propose a novel framework that generates graph embeddings for large designs (e.g., RISC-V) and incorporates various GNN models tailored for HT detection. Furthermore, our framework introduces domain-specific techniques for efficient training and inference by implementing model quantisation. Model quantisation reduces the precision of the weights, lowering the computational requirements, enhancing processing speed without significantly affecting detection accuracy.”
Evaluated on a custom dataset, the researchers found that a TROJAN-GUARD implementation quantized to four-bit precision to lower memory usage delivered a claimed precision of 98.66 per cent and a true-positive recall rate of 92.3 per cent. “These results,” the team concludes, “demonstrate the effectiveness and efficiency of our approach in accurately identifying hardware Trojans in complex chip designs, making it suitable for deployment in resource-constrained environments.”
A preprint of the team’s work is available on Cornell’s arXiv server under open-access terms.

News In Brief
- RISC-V RPMI Specification updated to v0.99, frozen after public review.
- ZeroRISC closes $10 million seed funding round.
- Paper: TYRCA - a RISC-V tightly-coupled accelerator for code-based cryptography. (Preprint PDF)
Have feedback or news for inclusion in a future newsletter? Please send this to ecl@fossi-foundation.org.
Subscribe to get El Correo Libre direct to your inbox.