
The Open-Source Z80 Lives
Renaldas Zioma responded, as did so many, with despair to the news that Zilog was to discontinue the venerable Z80 microprocessor - but decided to step up and rather than wallow created an open-source reimplementation manufactured as part of the Tiny Tapeout 07 run, and now proven to function as-expected.
“The Z80 is like a computer from my childhood,” Reneldas explains in an interview for the Zero to ASIC Course YouTube channel, “the ZX Spectrum. That’s the computer and microprocessor where I learned assembly, wrote small games, so it’s very much dear to me, in a way. Then the day I learned about Zilog discontinuing the Z80, I had this thought: we probably should do it in open-source now.”
Zilog launched the eight-bit Z80 in 1976 as its first commercial product, the work of former Intel engineer and company co-founder Federico Faggin and early employee Masatoshi Shima. It found a home in a range of devices, including a variety of home computers where it competed with MOS Technology’s 6502 family - and, up until Zilog’s discontinuation last year, remained a go-to choice for embedded systems.
With the part discontinued, a second-source was sought - and that’s where Reneldas’ work comes in. An open-source recreation was squeezed into four tiles of a Tiny Tapeout multi-project wafer, which was taped out in April last year for the SkyWater SK130 process node. Now, that tapeout has been proven functional: the chip has run a simple example app to count up on a seven-segment display.
“There’s still plenty of verification work ahead,” admits Tiny Tapeout’s Matt Venn of the project, “but it’s amazing to see this little chip alive and kicking.”
The design is detailed on the Tiny Tapeout website, with Reneldas’ interview available on YouTube.

16-Year-Old Developer Releases Open Icepi Zero FPGA Board
Developer Chengyin Yao has released an open-hardware design for a low-cost readily-accessible FPGA development board dubbed the Icepi Zero - at just 16 years of age.
“Currently most powerful FPGA boards on the market are expensive and bulky,” Chengyin explains. "I’ve always wanted a low-cost portable FPGA with video output to make my own CPU, but there isn’t any on the market.
“The Icepi Zero aims to fix this. Carrying a powerful ECP5 FPGA on a small Raspberry Pi Zero form factor, it is the ultimate portable solution for FPGA development. Additionally packing a HDMI- mini port and three USB-C ports, it allows interfacing with multiple external I/O devices.”
The board, with a layout inspired by the Raspberry Pi Zero family of single-board computers, features a Lattice ECP5U FPGA with 24k LUTs and 112kB of RAM, 256Mb of 166MHz SDRAM, 128Mb of flash storage, an HDMI-compatible display connector, three USB Type-C ports, a microSD Card slot, four user-addressable LEDs and a single user-addressable button, plus integrated USB JTAG and UART bridges.
“This powerful configuration allows the PCB to be used in numerous ways, including real time video processing, hardware AI acceleration and prototyping of ASICs. Icepi Zero is for everyone,” Chengyin pledges. Students can use it to learn about the internals of modern processors. Gamers can use it to emulate old hardware. Programmers can use it to test their code on multiple architecture. Icepi Zero also has an on-board USB to JTAG converter, so no external programmers are needed. Moreover Icepi Zero is fully open-source, no strings attached."
The project has been released on GitHub under the permissive Solderpad Hardware Licence v2.1.

Redwood EDA Launches First “ASIC Design Showdown”
Steve Hoover has reached out to let us know that his company, Redwood EDA, has launched the first in a planned new annual competition series: the Makerchip ASIC Design Showdown, open now.
“Designing semiconductors has been a game for big corporations for far too long, requiring deep expertise and access to expensive electronic design automation software,” Steve writes. "In recent years, free and open-source advancements in electronic design automation (EDA) are rewriting the rules. The Makerchip IDE leverages open-source EDA tools to deliver a powerful yet approachable experience for hobbyists.
"It’s time to have a little fun in this new, democratized world of semiconductors. The Makerchip ASIC Design Showdown challenges anyone and everyone to put their ingenuity to the test. We invite you to join in and show yourself and the world what you are capable of!"
The competition sees entrants working to create chip designs in challenges dubbed “arenas,” accessible directly in the Makerchip IDE. This year’s arena: Space Battle, in which a design must take control of a fleet of three spacecraft with the mission to hunt down their opponent’s fleet and destroy it. Entries are to be written in TL-Verilog or SystemVerilog, Steve explains.
Interested parties can find out more on the Redwood EDA website, and on the GitHub repository; registration must take place before the 26th of July and all designs must be made public by that time. The free-to-enter “Gamer’s Showdown” is scheduled to take place on the 1st of August; a paid “Gladiator’s Showdown,” at $40 per team until the end of the month, will take place on the 4th of August and include the chance to win prizes.
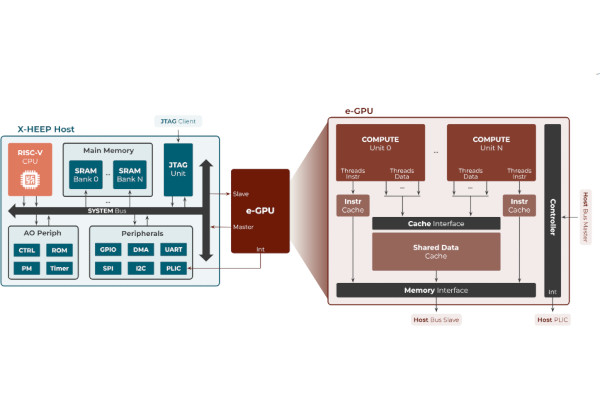
e-GPU Turns RISC-V into a GPU for TinyAI
Researchers from the Embedded Systems Laboratory (ESL) at EPFL, Lausanne, have developed a graphics processing unit (GPU) based on the free and open-source RISC-V instruction set architecture - not with gaming in mind, but as a way for running embedded artificial intelligence (AI) algorithms efficiently.
“Graphics processing units (GPUs) excel at parallel processing, but remain largely unexplored in ultra-low-power edge devices (TinyAI) due to their power and area limitations, as well as the lack of suitable programming frameworks,” the team explains. "To address these challenges, this work introduces embedded GPU (e-GPU), an open-source and configurable RISC-V GPU platform designed for TinyAI devices. Its extensive configurability enables area and power optimisation, while a dedicated Tiny-OpenCL implementation provides a lightweight programming framework tailored to resource-constrained environments.
"To demonstrate its adaptability in real-world scenarios, we integrate the e-GPU with the eXtendible Heterogeneous Energy-Efficient Platform (X-HEEP) to realise an accelerated processing unit (APU) for TinyAI applications. Multiple instances of the proposed system, featuring varying e-GPU configurations, are implemented in TSMC’s 16 nm SVT CMOS technology and are operated at 300MHz and 0.8V.
“The results demonstrate,” the researchers conclude, “that the high-range e-GPU configuration with 16 threads achieves up to a 15.1x speed-up and reduces energy consumption by up to 3.1x, while incurring only a 2.5x area overhead and operating within a 28mW power budget.”
A preprint of the team’s work is available on Cornell’s arXiv server; the researchers have pledged to make the complete code and all documentation available under an unspecified open-source license, but at the time of writing the project’s GitHub repository was not publicly accessible.

Brandon Li Goes Fundamental with a Semiconductor Simulator
Quantum physicist Brandon Li has written a simulator which goes somewhat more low-level than most, designed as it is to turn drawn semiconductor devices a detailed physical simulation.
“I created this simulator because I wanted to get a deeper understanding of how semiconductors work,” Brandon writes of the project. "It’s been my experience that there’s been a lack of good simulations that demonstrate advanced topics in physics. There certainly exists many educational physics simulations, but they’re all either aimed at lower educational levels, or they are very restricted in how the user can interact with the system. The only examples I’ve seen of simulations that combine advanced topics with a generous amount of interactivity are the physics applets written by Paul Falstad, to whom I’m also grateful for looking over my project and helping to convert it to JavaScript.
"My program simulates Maxwell’s equations on a two-dimensional grid. The electric field is tangent to the screen and the magnetic field points out of it. To evolve the E and B fields forward in time, I use Yee’s method. On top of this, I’ve added in semiconductors, which have two kinds of charge carriers, electrons and holes. Both types experience electric and chemical forces that determine their motion. The charge carrier density is determined by the continuity equation, with an extra term that describes recombination. When all this is put together, the result is a simulation that demonstrates many important properties of semiconductors.
“I’ve tried to give users many different ways of interacting with the simulation,” Brandon adds. “Circuits can be drawn with just a few clicks of the mouse, allowing users to easily experiment with their own circuits. There are also many different ways of visualising the underlying physics that I’ve incorporated into the settings. Each one gives a different perspective on the physics that is happening. At the end of the day, I think the best way to use my program is to just start playing around with it.”
The source code for the project is available on GitHub under the reciprocal GNU General Public Licence 3; a browser-based version is available on the author’s website.
IBM Turns an LLM into a VHDL Assistant
IBM researchers have published a paper detailing how a large language model (LLM) can be customised for a particularly domain-specific task: explaining VHDL code in the design of high-performance processors.
“The use of Large Language Models (LLMs) in hardware design has taken off in recent years, principally through its incorporation in tools that increase chip designer productivity,” the researchers say. "There has been considerable discussion about the use of LLMs in RTL specifications of chip designs, for which the two most popular languages are Verilog and VHDL. LLMs and their use in Verilog design has received significant attention due to the higher popularity of the language, but little attention so far has been given to VHDL despite its continued popularity in the industry.
"In this paper, we describe our journey in developing a Large Language Model (LLM) specifically for the purpose of explaining VHDL code, a task that has particular importance in an organisation with decades of experience and assets in high-performance processor design. We show how we developed test sets specific to our needs and used them for evaluating models as we performed extended pre-training (EPT) of a base LLM.
“Expert evaluation of the code explanations produced by the EPT model increased to 69% compared to a base model rating of 43%,” the researchers say of the experiment’s results. “We further show how we developed an LLM-as-a-judge to gauge models similar to expert evaluators. This led us to deriving and evaluating a host of new models, including an instruction-tuned version of the EPT model with an expected expert evaluator rating of 71%. Our experiments also indicate that with the potential use of newer base models, this rating can be pushed to 85% and beyond. We conclude with a discussion on further improving the quality of hardware design LLMs using exciting new developments in the generative AI world.”
The team’s paper is available as a preprint on Cornell’s arXiv server.
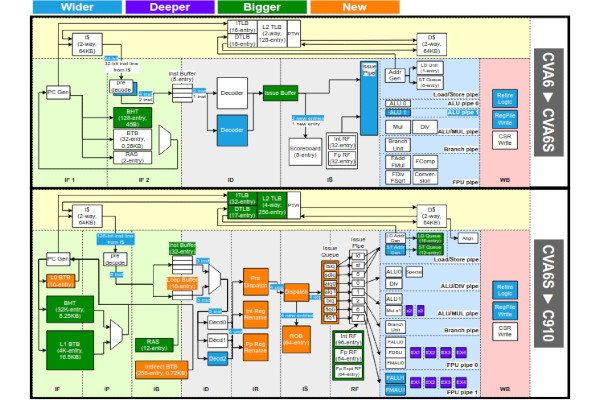
Researchers Release Faster, More Energy-Efficient RISC-V Cores
A team of researchers from ETH Zürich, the Università di Bologna, and the University Grenoble Alpes, Inria, have been hard at work on creating RISC-V designs optimised for performance and energy efficiency - releasing tweaked versions of the C910 and CVA6 cores as a result.
“Open-source RISC-V cores are increasingly demanded in domains like automotive and space, where achieving high instructions per cycle (IPC) through superscalar and out-of-order (OoO) execution is crucial,” the researchers say. "However, high-performance open-source RISC-V cores face adoption challenges: some (e.g. BOOM, Xiangshan) are developed in Chisel with limited support from industrial electronic design automation (EDA) tools. Others, like the XuanTie C910 core, use proprietary interfaces and protocols, including non-standard AXI protocol extensions, interrupts, and debug support.
"In this work, we present a modified version of the OoO C910 core to achieve full RISC-V standard compliance in its debug, interrupt, and memory interfaces. We also introduce CVA6S+, an enhanced version of the dual-issue, industry-supported open-source CVA6 core. CVA6S+ achieves 34.4% performance improvement over CVA6 core.
“The area and performance rankings of CVA6, CVA6S+, and C910 follow expected trends: compared to the scalar CVA6, CVA6S+ shows an area increase of 6% and an IPC improvement of 34.4%, while C910 exhibits a 75% increase in area and a 119.5% improvement in IPC,” the team concludes. “However, efficiency analysis reveals that CVA6S+ leads in area efficiency (GOPS/mm2), while the C910 is highly competitive in energy efficiency (GOPS/W). This challenges the common belief that high performance in superscalar and out-of-order cores inherently comes at a significant cost in area and energy efficiency.”
A preprint of the researchers’ work is available on Cornell’s arXiv server.

CHERI Looks Back on Ten Years of Progress
The CHERI (Capability Hardware Enhanced RISC Instructions) programme’s David Chisnall has taken a trip down memory lane with a look at what the wider CHERI and more focused CHERIoT programme, which aims to deliver memory safety for embedded systems in the Internet of Things, have achieved over the past decade.
“This week, we received an IEEE Security and Privacy Test of Time Award for the 2015 paper CHERI: A Hybrid Capability-System Architecture for Scalable Software Compartmentalization,” David writes. "For those less familiar with the history, the CHERI project started in 2010 (I joined in 2012) with the DARPA CRASH programme asking ‘If you could change anything about computing to improve security, what would you do?’ CHERI built on experiences with Capsicum and historical capability systems to reimagine memory safety.
"Looking back at the 2015 paper, it’s somewhat surprising how recognisable the system it describes would be for someone who is familiar with CHERIoT. A huge number of the features that make CHERIoT possible were there already. At the same time, it would be somewhat sad if CHERI had already been perfect in 2015 and it took another decade to get anything into production. Quite a few things have changed since then. Some are big, some are small refinements.
“CHERIoT started in 2019 and tried to scale the ideas down. The 2015 paper didn’t mention a 32-bit option at all. The 2018 CheriRTOS paper based on Hongyan Xia’s PhD work was, I think, the first public work to scale down to 32 bits. This had a lot of limitations from the encoding (Hongyan was one of the original CHERIoT team and we learned a lot from his experience). CHERIoT adds more kinds of sentries, temporal safety, a richer set of permissions, and closer co-design between the hardware and software.”
David’s full write-up is available on the CHERIoT website.
…and Offers a Roadmap to The Future
While David may have been looking at CHERI’s history, Mike Aftimakis of the CHERI Alliance has had his gaze fixed firmly forward - releasing a roadmap for the project’s future advancement, building on a study from the Defence Science and Technology Laboratory.
“In the rapidly evolving landscape of cybersecurity, the quest for robust and secure hardware foundations has never been more critical,” Mike writes. "A groundbreaking paper from the Defence Science and Technology Laboratory (DSTL) - Biting the CHERI bullet: Blockers, Enablers and Security Implications of CHERI in Defence - sheds light on the transformative potential of CHERI (Capability Hardware Enhanced RISC Instructions) technology, offering a beacon of hope for enhancing cyber resilience.
"Since the DSTL teams were new to CHERI, they found the learning curve difficult, because of inaccurate or missing documentation, lack of guidance, and a shortage of comprehensive examples. Again, although much progress has been done made since then and it is still an area that needs to improve: there is no practical reason why using CHERI should be difficult. Furthermore, amongst the millions of software developers worldwide, there is a broad variety of expertise, especially about the lowest levels of memory management, even more as the focus of education has shifted to high-level languages like Python. This lack of background knowledge might make understanding of memory safety issues more difficult.
“This stimulates us to focus our energy on this ‘developer enablement,’” Mike says, “where the CHERI Alliance would help get easier access to available documentation, but also create new content targeted towards different audiences. This is part of our mission to accelerate adoption of CHERI. A lot of experience has been accumulated by the teams working on CHERI for the past years (and some for more than a decade!), and we need to find the best ways to transfer this knowledge to the industry. At the moment, the Alliance is solving this by facilitating collaboration between experienced CHERI developers and new ones within the working groups and the various networking opportunities, but we indeed need to find more scalable ways to train the teams that need to update thousands (or even millions) of different products.”
Mike’s full roadmap is available on the CHERI Alliance blog; a preprint of the paper that triggered it is available on Cornell’s arXiv server.

Javier Orensanz Martinez Named as lowRISC CEO
lowRISC has announced a change at the top, naming Javier Orensanz Martinez as incoming chief executive officer as Gavin Ferris steps down after five years in the role pro bono.
“Serving as the CEO of lowRISC for five years has been a tremendous privilege and a role I have greatly valued,” says Gavin of his past half-decade. “I’m very proud of what we have achieved alongside our partners during this time - not least in having helped bring the first commercial open-source silicon to reality, with production OpenTitan chips going into Chromebook sockets this summer, Google datacentre applications to follow, and Rivos (and others) integrating the IP directly into their SoC. I’m confident that in handing the reins over to Javier, his drive and experience will help propel lowRISC to the next level, build on the achievements we’ve accomplished with our valued partners already, and further the positive impacts of open-source silicon.”
“I am so impressed with everything that Gavin and the lowRISC team have accomplished in the last 10 years in collaboration with its amazing partners and contributors,” adds Javier, who joins the community interest company from a 22-year career at Arm. “I am thrilled to join the organisation at such a pivotal time, with the first OpenTitan root-of-trust silicon having hit production, and look forward to building on its solid foundations to boost the adoption of open-source hardware.”
“The Board and I would like to thank Gavin for his excellent leadership these last five years and recognise the tremendous accomplishments he and the team have made in open-source silicon,” says Sir Andy Hopper, lowRISC’s independent chair, of the appointment. “And we are thrilled to welcome Javier as the new CEO - his deep experience in the open-source and semiconductor space and proven track record of success in this industry aligns perfectly with lowRISC’s mission. This is a fantastic time for him to take lowRISC to the next stage of its journey and seize the opportunities available.”
Gavin and Javier will act as co-CEOs throughout June, the company has announced, before Javier takes over at the end of the month.

News In Brief
- Angelo Jacobo has expanded UberDDR3 to include support for the Lattice ECP5 FPGA family.
- Andrea Gallo named as the new RISC-V International chief executive officer.
- RISC-V Summit North America 2025 Call for Proposals now open.
Have feedback or news for inclusion in a future newsletter? Please send this to ecl@fossi-foundation.org.
Subscribe to get El Correo Libre direct to your inbox.