
First Speakers Confirmed for Latch-Up 2023 in Sunny Santa Barbara
The FOSSi Foundation is proud to announce the first batch of speakers confirmed for Latch-Up 2023, our conference dedicated to free and open-source silicon - taking place this year in sunny Santa Barbara, California, USA.
Come and join us to learn about new RISC-V cores, open source silicon in space, brain-inspired neuromorphic accelerators, novel tooling for rapid ASIC/FPGA design and much more. And of course, everything you will see is open source.
Among the speakers confirmed for this year's Latch-Up conference are: Wenting Zhang, who will be introducing an in-order non-blocking dual-issue 64-bit RISC-V design recently taped out on Skywater's SKY130 process; Graeme Smecher, who will be walking through the compressed-first microcoded RISC-V CPU Minimax; Jerry Zhao, talking about the open-source Chisel generator for network-on chip interconnects Constellation; and Andreas Olofsson, showcasing the SiliconCompiler which aims to drop the barrier to hardware development as low as that for software.
Other confirmed speakers include: Chinh Le, who will be looking at past and future uses for open-source silicon off-planet; Jason Eshraghian's work on neuromorphic accelerator ASICs inspired by the human brain; Sagar Karandikar on FireSim, a scalable platform for FPGA-accelerated simulation, debugging, and profiling of RTL designs; Abraham Gonzalez discussing the open-source RISC-V system-on-chip design framework Chipyard; Camilo Soto on his journey from zero experience to taping out a systolic array; and Srinivasan Venkataramanan, who will be talking about his team's experience in porting production SystemVerilog Checker IPs to Verilator.
With more speakers to be announced in the coming weeks, now is a great time to register to attend through the official website - and it's entirely free for individuals, though paid-for professional tickets and sponsorship opportunities are still available for those whose companies would like to support the conference. If that's you, please get in touch to discuss!
Latch-Up 2023 takes place at the University of California, Santa Barbara (UCSB) on Friday the 31st of March through to Sunday the 2nd of April. You can find out more on the website, and we look forward to a catch-up at Latch-Up!

QuickLogic Launches New Aurora Tool Suite, Built Atop Open Source Projects
Embedded FPGA specialist QuickLogic has announced the release of version 2.1 of its Aurora Development Tool Suite package, which is built atop popular open-source projects including Yosys and OpenFPGA.
"QuickLogic remains committed to open source, and our new Aurora 2.1 Development Tool Suite underscores that mission," claims Mao Wang, senior director of product development at QuickLogic, of the company's new launch. "Now, SoC developers can combine the advantages of open-source tools with the dramatic flexibility benefits of embedding FPGA technology into their devices to improve device lifecycles and enhance profitability."
The new Aurora 2.1 is built on top of the Yosys open synthesis suite, the Versatile Place and Route (VPR) sub-project of Verilog-to-Routing, and the OpenFPGA framework - all integrated into a user experience designed to be familiar to existing QuickLogic users.
Moving away from proprietary solutions and towards open source means, the company says, "higher quality software" over which "the user has ultimate control."
Aurora 2.1 is available from QuickLogic now, with more information available on the company's website.
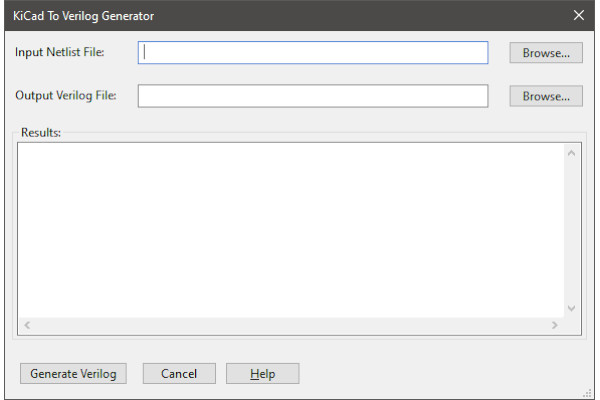
Bob Alexander's Plug-in Generates Verilog from a KiCad Schematic
Bob Alexander has created a plug-in for the popular KiCad computer aided design software which turns schematics in a Verilog framework - though relies on the user to make the output functional.
"Why would anyone want such a thing? In my case, I’m designing a homebrew CPU," Bob explains. "I wanted to simulate it before fabricating the PCB. Generating Verilog, and using one of the many Verilog simulators that are available, seemed like the best approach.
"There are some Verilog design packages, like Quartus II and Icestudio, that allow you to draw a schematic. But their schematic tools are not as powerful as KiCad’s. And once you’re done drawing and testing in those packages, you need to go through the tedious and error-prone process of re-drawing the schematic in a PCB CAD program anyway."
The plug-in, however, only gets you part of the way to a solution. "It generates a framework for a working Verilog program," Bob explains, "with Verilog modules for all the components, and Verilog wires for all the connections. But it doesn’t know the behaviour of the components in the schematic. So the user is still responsible for writing Verilog for each component."
The plug-in is available on GitHub now, under the permissive MIT licence.
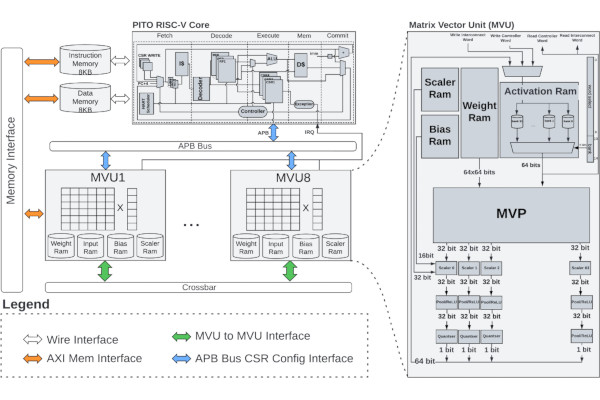
BARVINN is a Deep Neural Network Accelerator with Arbitrary Precision
Researchers at the Ecole Polytechnique Montreal, IBM, Mila, and CMC Microsystems have published a paper detailing the Barrel RISC-V Neural Network Accelerator Engine BARVINN - RISC-V-controlled deep neural network (DNN) accelerator promising arbitrary precision support using bit-serial computation.
"One way to accelerate computation in a deep neural network is to use less precision for computation," the team explains. "To benefit from quantization in a neural network, one must use a hardware that supports low precision computation.
"At the time of writing this documentation, there are no commercially available general processors (CPU or GPU) that can efficiently store and load sub-8-bit parameters of a neural network. Also, the general processors are not equipped with customized hardware to perform arbitrary precision computation. Hence, to fully benefit from quantization, one should consider designing custom ASICS."
This is where BARVINN comes in. Built around eight processing elements with a RISC-V controller core, and designed using FuseSoC, BARVINN is capable of operating at arbitrary precision - including sub-8-bit. "BARVINN performs GEMM/GEMV, Convolutions, Maxpooling, and Activation (ReLU)," its creators explain.
"We have actually done a GlobalFoundries 22nm synthesis," first author Hossein Askari writes, "and are planning to do a GF 12nm synthesis as well. However, no tape-out yet. I might do a GF180 (at least for the RISC-V core) if I get time."
A preprint copy of the BARVINN paper is available on Cornell's arXiv server, while the full source code has been released on GitHub under the permissive MIT licence.
Antmicro Releases Alkali, an Open-Source NVMe ML Accelerator Platform
Antmicro has announced the release of Alkali, a platform developed with Western Digital for in-storage machine learning acceleration projects based around the Berkeley Packet Filter (BPF) - with which it hopes people will be able to developer custom computational storage devices.
"Computational storage is particularly useful for unstructured data, i.e. images, videos, or audio," the company explains. "With computational storage devices (CSD), deep learning models can be deployed for incoming data to e.g. detect, annotate and track objects present in images or video files. With the metadata coming from deep learning models, analysis and management of unstructured data can become much easier and faster."
The Alkali platform is split across four major components: a PCI Express (PCIe) core which communicates with the NVMe target controller; said target controller, which is designed to run on a real-time processing unit (RPU); a software stack for custom NVMe commands and running the accelerators themselves; and shared DDR memory used by both the application-class cores which run the software and the RPU cores.
"For accelerating deep learning operations on the Alkali platform, we used the Versatile Tensor Accelerator (VTA) - an open source deep learning accelerator deployable on FPGAs," Antmicro adds. "It is a parametrisable design that accelerates dense linear algebra operations. As a runtime for deep learning models in BPF VM, we decided to use TensorFlow Lite, with which we also work in other contexts."
More information is available on the Antmicro blog, while an automated build system for a demo targeting Xilinx' Zynq UltraScale+ MPSoC XCZU7EV chips is available on GitHub. A separate repository contains firmware source code under the permissive Apache 2.0 licence, with a third repository hosting the FPGA design files.
 )
)
Olof Kindgren Announces the Release of FuseSoC 2.0
FOSSi Foundation director Olof Kindgren has announced the milestone 2.0 release of FuseSoC, the award-winning package manager and build tool set for hardware description language projects.
"It finally happened. After almost two years, FuseSoC 2.0 is released," Olof says of the launch. "Thank you to everyone who helped out. I counted to 16 people sending patches and there are many more who helped by filing bugs or coming with suggestions."
The new release bumps the minimum compatible Python version to 3.6, improves its usability as a module, supports the Integer type in tool options, can copy directories and run generators in uniquely-named temporary directories, adds support for virtual packages in CAPI2, adds support for the Edalize flow API, and comes with improved documentation.
The latest FuseSoC release also brings with it a few removals, including the loss of CAPI1 support and the removal of the deprecated logicore and coregen providers as well as the config options cores_root and systems_root.
The latest release is available on the FuseSoC GitHub repository now, along with the full source code under the permissive BSD 2-Clause licence.
GHAZI Uses a Completely Open-Source Path to Build a RISC-V SoC
A team of researchers from Pakistan's UIT University have published a paper detailing GHAZI, a minimalist RISC-V system-on-chip designed and taped-out for manufacturing using wholly open-source tools.
"This paper presents a methodology of adapting complete open-source digital tooling, ISA, IPs, and manufacturable PDKs Process Design Kits to tape-out a minimalist RISC-V based SoC named GHAZI," the team explains. "The methodology uses an RV32IMC core and an SoC reference design from OpenTitan (Ibex core and peripherals respectively) at base, adding instruction and data memories, converting the design into Verilog for the RTL to GDSII flow with open-source tools, alongside an FPGA implementation for Xilinx Arty-7 FPGA, finally generating the GDSII layout using OpenLane on Skywater 130nm PDK.
"Verification was done on all stages, i.e. RTL, gate level simulations and LVS, before integrating GHAZI-SoC with Caravel, the template SoC design for the Open Multi-Process Wafer (Open-MPW) shuttle."
The resulting GHAZI system-on-chip uses over 90,000 physical cells in a 6.9mm² die area and runs at 12.5MHz based on a 1.8V supply. After the design was prototyped in FPGA, it was physically produced under the Open-MPW programme - with Google paying the fabrication costs.
The team's work has been published as a preprint on TechRxiv, though at the time of writing a promised GitHub repository containing the GHAZI sources could not be located.

Renode Gains Verilator-Powered CPU RTL Co-Simulation Capabilities
Antmicro's simulation framework Renode, which has long been able to use Verilator to offer co-simulation capabilities, has gained the ability to simulate CPUs directly from RTL for increased flexibility.
"Support for Verilator in Renode has been expanded to allow CPUs simulated directly from RTL, which opens an array of new possibilities for developing new CPU core IP and combining it with Renode’s vast portfolio of peripheral IP for a complete system able to run advanced software," the company claims.
"While previously developed HDL components provided some level of interactivity, like UART reacting on input and generating an interrupt or DMA initiating a transfer on a bus, the verilated CPU takes it to a whole new level of complexity."
The functionality, available now, allows an RTL CPU model to be added into a Renode platform as a component indistinguishable from non-RTL CPU models previously supported - and the user is free to easily switch between the two, the company promises.
More information is available on the Antmicro blog, with the source code for samples available on GitHub under the permissive MIT license.
Xan Phung's "Alternative" RV128 Vision Proposes Skipping Over RV64
Xan Phung has published a proposed "alternative" version of RV128, the 128-bit version of the RISC-V instruction set architecture, which would provide a direct upgrade path for current users of 64-bit non-RISC-V ISAs - skipping over RV64 altogether.
"My proposal assumes the first high volume market to adopt 128-bit computing will be data centres/cloud services & 128-bit personal computer CPUs," Xan explains of his reasoning. "In both these markets, x86_64 has overwhelmingly the largest installed base, with trillions in sunk costs by 2030 (AWS, Azure, GCP alone > $500bil).
"My vision for RV128 sees it as a 'feature add-on' to legacy 64-bit systems (and there is no benefit in an RV64 intermediate transition). However, 'pure' or greenfield implementations of my RV128 are also possible - the important point is not to prematurely foreclose on either choice."
Xan's vision for RV128 includes energy efficiency gains by going straight to 128-bit registers, the dropping of the link register from the current RV128 design in order to offer cross-compatibility between RV64 and RV128 code, and the option of "pure" and "mixed" variants with the latter being embedded in a host ISA using a prefix.
"I believe we need to start thinking about 128-bit systems from today, as the barrier is not silicon/transistor budget cost, nor is it waiting for 128-bit memory addressing," Xan explains. "All it will take is that we change our own historical mindset (that 128-bit is far off into the future), and think of practical/incremental ways to build & use 128-bit datapaths right now."
A discussion surrounding Xan's proposal is available on the RISC-V ISA Dev mailing list.
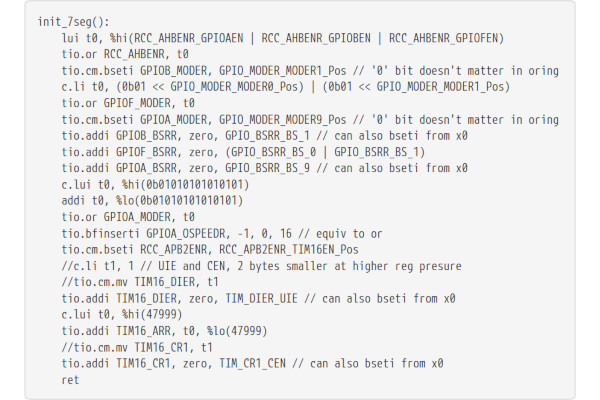
Jan Oleksiewicz's RISC-V Extension Offers Directly-Accessed Peripheral Registers
A custom RISC-V extension, XTightlyCoupledIO, by Jan Oleksiewicz aims to provide direct accessed peripheral registers - similar in concept to those available in AVR and PRU microcontroller platforms.
"I have made a new custom extension providing AVR8/PRU like IO instructions," Jan explains of his project. "It is designed for accessing peripheral registers in microcontrollers. The scope of the XTightlyCoupledIO extension is to reduce code size, register pressure and increase performance in peripheral accessing code. All of which results in reduced latency in control loops, etc."
Jan's project was inspired by the 64 IO registers available in AVR8, as implemented on popular Microchip microcontrollers including the ATmega328P popularised by the Arduino Uno platform, as well as Texas Instruments' Programmable Real-time Units (PRUs) and the Programmable Input/Output (PIO) blocks in the Raspberry Pi RP2040 microcontroller.
"The encodings are currently temporary until instruction set stabilises," Jan warns anyone looking to try the extension out for themselves. "There are also some tooling issues to resolve."
The proposal source, and rendered PDFs, is available on GitHub under the Creative Commons Attribution 4.0 licence.

FOSSi News In Brief
- Krste Asanović announces the public review period for Zvfh, Zvfhmin RISC-V extensions, ends 10th March 2023.
- Intel's Pathfinder for RISC-V Programme closes down, less than six months after launch.
- Sophia Chen, MIT Technology Review: "A Chip Design That Changes Everything."
- Kristin Houser, Freethink: "An Open-Source Option is Shaking Up the Microchip Industry."
- Brian Bailey, Semiconductor Engineering: "What Does 2023 Have In Store for Chip Design?"
Have feedback or news for inclusion in a future newsletter? Please send this to ecl@librecores.org.
Subscribe to get El Correo Libre direct to your inbox.